前言
这个实践方案来自我自己的需求——网站首页需要图片背景,然而,放两张固定图未免显得有些枯燥乏味,网上其他的随机图 API 则质量良莠不齐,风格不统一,更重要的是加载速度不够稳定,偶尔遇上抽风,就会严重影响首页的加载速度和浏览体验。
实际上,对于自建随机图片 API,全网已经有不少成熟方案,大部分情况下,我们只需要 copy 过来做简单修改即可,但浏览一圈,对比我自己的需求,大部分方案如果要用,都得进行不小的更改。因此,考虑到功能不算复杂,我决定自己亲自动手设计。
我的需求
设计之前,得先明确需求,但在这之前,我们不妨先来梳理一下,一个随机图片 API 是如何工作的。
访问者首先输入 API 的调用域名,通过配置好的 DNS 解析连接到对应的服务器 IP,服务器调出对应页面,再根据页面的处理逻辑来返回图片资源。
这个流程最重要的部分有两处:一个是存储图片的资源库,一个是 API 的主页面,我们的需求也主要是针对这两个部分。
首先,对于图片库,我希望它能够建立在 API 服务器之外的其他云端存储容器上,以远程读取的方式实现调用, 原因也很好理解:服务器的存储空间本身“寸土寸金”,把这些容量单纯拿来放图片,实在是有些浪费;其次,服务器本身如果要实现高频、快速的图片读取,要花费额外的时间做优化,但很多第三方云存储平台(如腾讯云 COS、阿里云 OSS、又拍云存储等)已经考虑到用户将其作为图床的使用需求,针对图片调取已经有了很多省心的设计(比如能够一键开启的 Referer、User-Agent 等多种形式的防盗链、方便的 CORS 跨域请求配置等),既然如此,我们当然应该善加利用。
确定了图片库的部署位置,接下来我们就该确定 API 应该实现的功能,在最初阶段,我希望它至少能够实现以下几点:
- 对接图片库,实现定时自动同步
- 针对来自不同的设备调用请求,能够返回不同比例的图片(图片自适应)
在此基础上,我们就可以开始正式设计了。
建立图片库+API 设计
我个人使用的是又拍云存储,所谓的建立存储库,无非也就是把图片上传到里面而已,但在此过程中,还是有一些需要注意的地方: 首先,图片在上传时就应该分门别类地存放,这样在设计调用逻辑时会减少很多无谓的麻烦。 像我就只依据比例做了宽屏和窄屏的区分,把他们放在不同的文件夹,如果你有更高级的需求(比如需要依据题材或画风分类调用),那就可能需要做更精细的分类;其次,图片的质量、格式最好在上传前或上传时就进行统一,以免在调用时出现问题。 我的图片用于网页,所以我一般习惯在上传时统一将其转换成浏览器支持的、更小更先进的 webp 格式,同时设置压缩质量为 75% 以适当控制大小(相信我,你不会想看到 20MB 的图片在你的首页一块一块加载的),这部分各位可以根据需求自行调整。
上文提到,云存储平台往往有自己支持的各类接口,因此,我们可以通过这些接口对内容进行远程调用,实现我们想要的效果。所以,是不是我们只要在收到调用请求后,不停地通过接口返回图片就可以了呢?理论上似乎行得通,但这对接口的负担未免太重,更何况,大多数此类接口都有频次限制,短时间高频调用,难免会出现各种各样的问题——也许,还有更好的思路?
事实上,如果在云存储平台绑定了域名,其中的所有的资源都会有一个唯一的访问链接,通过链接访问图片,就和通过域名访问服务器资源是一样的。所以,如果我们只是通过接口,获得对应文件夹内所有图片的访问连接,再在收到调用请求时通过该链接返回图片,不就能避免对接口的高频调用了吗?
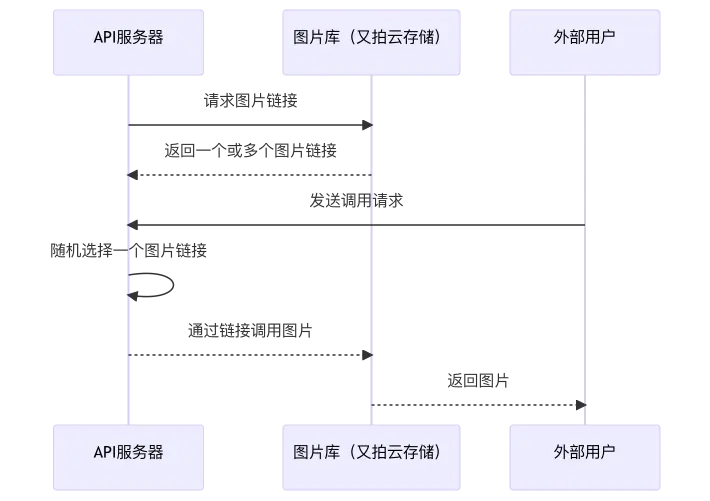
运行流程
这似乎是个不错的思路,围绕这一点,经过规划,我将 API 的运作分为了两大模块:
- 获取图片链接。以又拍云存储为例,文件的链接形式一般是“自定义域名 + 文件夹路径 + 文件名”,只要通过调用接口,遍历特定文件夹下文件的路径和名称,再与自定义域名进行 url 拼接,即可获得其访问链接,将其存储在 API 服务器上,即可作为调用图片的地址来源。这一部分的功能可以通过简单的脚本完成,设置成定时任务,即可实现定时文件同步。
- 调用图片。有了第一步存储的地址,我们就可以把调用的目标设置为存储有链接的本地文件,通过随机逻辑返回不同链接的内容,即可完成“调用随机图片”的动作。但在这一步之前,我们还需要解决发起请求的设备判断问题。
鉴于我正在使用 wordpress 博客系统,服务器上已经有 php 环境,因此我选择了又拍云的 PHP SDK 完成此任务。同时,又由于本人的 php 水准实在够呛,因此,大部分的代码实际上由 AI 编写,此处放出,仅供参考:
获取图片链接(部分):
<?php
require_once '/file path/autoload.php';
use Upyun\Upyun;
use Upyun\Config;
// 初始化又拍云服务配置
$serviceConfig = new Config('bucket', 'user', 'key');
$client = new Upyun($serviceConfig);
// 目录路径
$pcPath = '/file path/pc/';
$mobilePath = '/file path/mobile/';
// 获取图片 URL(生成半成品 URL)
function getImageUrls($client, $path) {
$urls = [];
$response = $client->read($path, null, ['X-List-Iter' => '', 'X-List-Limit' => 100]);
if (!empty($response) && is_array($response) && isset($response['files']) && is_array($response['files'])) {
foreach ($response['files'] as $item) {
if (is_array($item) && isset($item['name']) && $item['type'] === 'N') {
// 生成半成品 URL(不含格式转换参数)
$halfUrl = $path . '/' . $item['name'];
$urls[] = $halfUrl;
}
}
}
return $urls;
}
// 获取图片 URL 并保存到 txt 文件
$pcUrls = getImageUrls($client, $pcPath);
$mobileUrls = getImageUrls($client, $mobilePath);
// 保存半成品 URL 到 txt 文件
saveUrlsToTxt($pcUrls, '/file path/half_pc.txt');
saveUrlsToTxt($mobileUrls, '/file path/half_mobile.txt');
function saveUrlsToTxt($urls, $filePath) {
if (!empty($urls)) {
$content = implode("\n", $urls);
file_put_contents($filePath, $content);
}
}URL 拼接,获得完整链接:
#!/bin/bash
# 定义半成品txt文件的路径
HALF_PC="/file path/half_pc.txt"
HALF_MOBILE="/file path/half_mobile.txt"
# 定义最终txt文件的路径
FINAL_PC="/file path/pc.txt"
FINAL_MOBILE="/file path/mobile.txt"
# 定义又拍云的域名
UPYUN_DOMAIN="domain"
# 清空最终文件
> "$FINAL_PC"
> "$FINAL_MOBILE"
# 函数:为URL添加.webp参数,如果URL不以.webp结尾
addWebpParam() {
local path="$1"
local name="$2"
# 构造完整的URL
local formattedUrl="${UPYUN_DOMAIN}${path}${name}"
# 如果文件扩展名不是.webp,则添加参数
if [[ $name != *.webp ]]; then
formattedUrl="${formattedUrl}!/format/webp"
fi
echo "$formattedUrl"
}
# 构造PC图片的最终URL并保存到最终txt文件
echo "Processing PC images..."
while IFS= read -r line || [ -n "$line" ]; do
# 读取路径和文件名
path="${line%/*}"
name="${line##*/}"
# 构造合法URL并在最后添加参数
finalUrl="$(addWebpParam "$path" "$name")"
echo "$finalUrl" >> "$FINAL_PC"
done < "$HALF_PC"
# 构造Mobile图片的最终URL并保存到最终txt文件
echo "Processing Mobile images..."
while IFS= read -r line || [ -n "$line" ]; do
# 读取路径和文件名
path="${line%/*}"
name="${line##*/}"
# 构造合法URL并在最后添加参数
finalUrl="$(addWebpParam "$path" "$name")"
echo "$finalUrl" >> "$FINAL_MOBILE"
done < "$HALF_MOBILE"
# 清空半成品txt文件
echo "Clearing half product files..."
> "$HALF_PC"
> "$HALF_MOBILE"
# 连接到Redis
echo "Connecting to Redis..."
redis-cli -h 127.0.0.1 -p 6379
# 清空Redis中的图片链接集合
echo "Clearing Redis sets..."
redis-cli -h 127.0.0.1 -p 6379 del pc_images > /dev/null 2>&1
redis-cli -h 127.0.0.1 -p 6379 del mobile_images > /dev/null 2>&1
# 从txt文件中读取链接并存储到Redis
echo "Populating Redis with image URLs..."
while IFS= read -r line || [ -n "$line" ]; do
redis-cli -h 127.0.0.1 -p 6379 sAdd pc_images "$line" > /dev/null 2>&1
done < "$FINAL_PC"
while IFS= read -r line || [ -n "$line" ]; do
redis-cli -h 127.0.0.1 -p 6379 sAdd mobile_images "$line" > /dev/null 2>&1
done < "$FINAL_MOBILE"
echo "Processing complete."API 主页面:
<?php
require_once '/file path/autoload.php';
//通过获取 User-Agent 判断设备类型
$userAgent = $_SERVER['HTTP_USER_AGENT'];
$isMobile = preg_match('/(android|iphone|ipad|ipod|blackberry|windows phone)/i', $userAgent);
// 选择 txt 文件路径(自适应返回图片)
$txtFilePath = $isMobile ? '/file path/mobile.txt' : '/file path/pc.txt';
// 尝试从 Redis 获取图片链接
$redis = new Redis();
$redis->connect('127.0.0.1', 6379); // 根据你的 Redis 服务器地址和端口进行调整
$key = $isMobile ? 'mobile_images' : 'pc_images';
$randomUrl = $redis->sRandMember($key);
// 如果从 Redis 获取失败,则从 txt 文件中读取
if ($randomUrl === false) {
// 读取 txt 文件中的 URL 并随机选择一个
$urls = file($txtFilePath, FILE_IGNORE_NEW_LINES | FILE_SKIP_EMPTY_LINES);
if (!empty($urls)) {
$randomUrl = $urls[array_rand($urls)];
} else {
header('Content-Type: text/plain');
echo "No images available.";
exit;
}
}
// 获取图片内容
$imageContent = file_get_contents($randomUrl);
// 检查是否成功获取图片内容
if ($imageContent === false) {
header('Content-Type: text/plain');
echo "Failed to retrieve image content.";
exit;
}
// 获取图片的 MIME 类型
$imageInfo = getimagesize($randomUrl);
$mime = $imageInfo['mime'] ?? 'application/octet-stream'; // 如果无法获取 MIME 类型,则默认为 application/octet-stream
// 输出图片内容
header('Content-Type: ' . $mime);
echo $imageContent;计划任务命令(定时更新链接):
/usr/bin/php /file path/get-url.php && /file path/url.sh优化
当然,上面的代码中还有一些之前没有提到的部分,这是后来做的一点额外改进。此外,还有一些我计划想要加入的优化,现在还没有添加进去,也一并写出来,有能力的读者可以自己实现。
性能优化
在最开始设计的处理流程中,我把图片的调用链接存储在 API 服务器上的 txt 文件里,相比直接把图片存在服务器里,读取负担已经小了很多,但这是不是就是最好的方法了呢?
我们知道,在更大型的项目中,对于那些需要高频读写的文件,我们一般会把它放在缓存中,比起受限于 I/O 的硬盘读写,缓存读写的性能要高不止一个数量级,所以,我们为什么不采用这种方式来存储链接呢?
可以看到,在上面的代码中,我使用了基于 Redis 的服务器缓存来实现这一目标,获取链接后,先将其写在 txt 文件中,随后再存进 Redis 缓存里,之后直接从缓存里读取链接,仅在缓存被清理或出现问题时,才会从 txt 中读取,从而能够提高整体的响应速度。
各位可以回顾 API 的整个处理逻辑,我相信其中的每一步都还有再优化的空间,本文提到的部分只能算是抛砖引玉,有能力的读者可以尝试设计自己的改进方案。
处理逻辑优化
首先要说的是,我的代码其实缺了一个很重要的部分——错误处理。
是的,这本是设计之初就应该考虑的重要问题,我却不知为何直接略过了这一部分,希望各位以我为戒😣。
如果 API 因为某种原因无法读取到任何链接,它应该如何回应调用请求?如果链接是无效链接,或者并不包含图片内容,又该如何处理?这些都是应该要考虑的问题。
除此之外,各位也可以尝试做一些功能性的改进,例如,有没有可能在调用时附带一些参数,指定需要的图片的宽高比?或者让 API 不返回图片本身,而是返回图片的 exif 信息?
总而言之,这个项目虽然小,但有很多发挥的空间和改进的余地,很适合作为新手搭建在线业务的练习,建议各位自己上手玩玩看,也许从此就踏入了一方新天地也说不定(笑)。
